本文共 6048 字,大约阅读时间需要 20 分钟。
索引、触发器、存储过程、连接、死锁机制、数据库的恢复、备份、union、MySQL引擎
索引
- 索引是什么?
索引是对数据库表中一列或多列的值进行排序的一种结构,使用索引可快速访问数据库表中的特定信息。索引是经过某种算法优化过的,因而查找次数要少的多。可见,索引是用来定位的。数据库索引好比是一本书前面的目录,能加快数据库的查询速度。
索引分为聚簇索引和非聚簇索引两种,聚簇索引是按照数据存放的物理位置为顺序的,而非聚簇索引就不一样了;聚簇索引能提高多行检索的速度,而非聚簇索引对于单行的检索很快。根据数据库的功能,可以在数据库设计器中创建三种索引:唯一索引、主键索引和聚集索引。
唯一索引:是不允许其中任何两行具有相同索引值的索引。
主键索引:数据库表经常有一列或多列组合,其值唯一标识表中的每一行,该列称为表的主键。在数据库关系图中为表定义主键将自动创建主键索引,主键索引是唯一索引的特定类型。该索引要求主键中的每个值都唯一。当在查询中使用主键索引时,它还允许对数据的快速访问。
聚集索引:在聚集索引中,表中行的物理顺序与键值的逻辑(索引)顺序相同。一个表只能包含一个聚集索引。,聚集索引比非聚集索引提供更快的数据访问速度。举例:聚集索引:字典中的默认按字母顺序排序;非聚集索引:字典中按偏旁部首定位某个生僻字。
提示:尽管唯一索引有助于定位信息,但为获得最佳性能结果,建议改用主键或唯一约束。
- 索引的创建方法
CREATE INDEX mytable_categoryid ON mytable (category_id);CREATE INDEX mytable_categoryid_userid ON mytable(category_id,user_id);
只要数据库认为可以使用某个已经创建的索引,索引就会自动运用。
create index idx_emp_ename on EMP(ename); select *from EMP where ename='SMITH';
- 索引的内部原理
B+tree 是一个n叉树,每个节点有多个叶子节点,一颗B+树包含根节点,内部节点,叶子节点。根节点可能是一个叶子节点,也可能是一个包含两个或两个以上叶子节点的节点。所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
由于B+tree的性质, 它通常被用于数据库和操作系统的文件系统中。NTFS, ReiserFS, NSS, XFS, JFS, ReFS 和BFS等文件系统都在使用B+树作为元数据索引,
因为B+树的特点是能够保持数据稳定有序,其插入与修改拥有较稳定的对数时间复杂度(B+ 树元素自底向上插入)。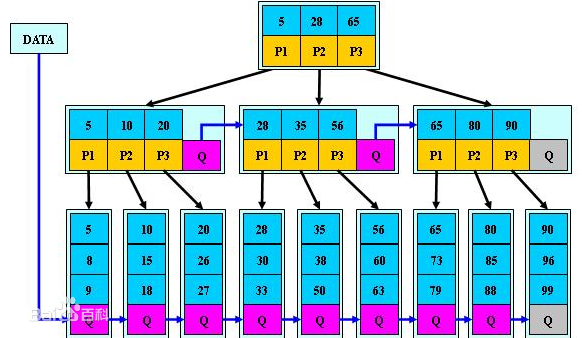
-
索引的优缺点
数据库索引就是为了提高表的搜索效率而对某些字段中的值建立的目录 。 优点:加快对表中记录的查找或排序。 缺点:1.增加了数据库的存储空间;2.当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。 -
使用时的注意事项
每次给字段建一个新索引, 字段中的数据就会被复制一份出来, 用于生成索引。 因此, 给表添加索引,会增加表的体积, 占用磁盘存储空间。 非聚集索引和聚集索引的区别在于, 通过聚集索引可以查到需要查找的数据, 而通过非聚集索引可以查到记录对应的主键值 , 再使用主键的值通过聚集索引查找到需要的数据。
不管以任何方式查询表, 最终都会利用主键通过聚集索引来定位到数据, 聚集索引(主键)是通往真实数据所在的唯一路径。
然而, 有一种例外可以不使用聚集索引就能查询出所需要的数据, 这种非主流的方法 称之为「覆盖索引」查询, 也就是平时所说的复合索引或者多字段索引查询。
触发器
- 触发器是什么?
触发器是与表有关的数据库对象,在满足定义条件时触发,并执行触发器中定义的语句集合。触发器的这种特性可以协助应用在数据库端确保数据的完整性。
举个例子,比如你现在有两个表【用户表】和【日志表】,当一个用户被创建的时候,就需要在日志表中插入创建的log日志,如果在不使用触发器的情况下,你需要编写程序语言逻辑才能实现,但是如果你定义了一个触发器,触发器的作用就是当你在用户表中插入一条数据的之后帮你在日志表中插入一条日志信息。当然触发器并不是只能进行插入操作,还能执行修改,删除。
- 如何创建触发器?(基于MySQL)
创建触发器语法结构
CREATE TRIGGER trigger_name trigger_time trigger_event ON tb_name FOR EACH ROW trigger_stmttrigger_name:触发器的名称tirgger_time:触发时机,为BEFORE或者AFTERtrigger_event:触发事件,为INSERT、DELETE或者UPDATEtb_name:表示建立触发器的表明,就是在哪张表上建立触发器trigger_stmt:触发器的程序体,可以是一条SQL语句或者是用BEGIN和END包含的多条语句所以可以说MySQL创建以下六种触发器:BEFORE INSERT,BEFORE DELETE,BEFORE UPDATEAFTER INSERT,AFTER DELETE,AFTER UPDATE
创建有多个执行语句的触发器
CREATE TRIGGER 触发器名 BEFORE|AFTER 触发事件ON 表名 FOR EACH ROWBEGIN 执行语句列表END
其中,BEGIN与END之间的执行语句列表参数表示需要执行的多个语句,不同语句用分号隔开
tips:一般情况下,mysql默认是以 ; 作为结束执行语句,与触发器中需要的分行起冲突
为解决此问题可用DELIMITER,如:DELIMITER ||,可以将结束符号变成||
当触发器创建完成后,可以用DELIMITER ;来将结束符号变成;
mysql> DELIMITER ||mysql> CREATE TRIGGER demo BEFORE DELETE -> ON users FOR EACH ROW -> BEGIN -> INSERT INTO logs VALUES(NOW()); -> INSERT INTO logs VALUES(NOW()); -> END -> ||Query OK, 0 rows affected (0.06 sec)mysql> DELIMITER ;
具体使用举例:创建一个新用户时,插入一条log日志
DELIMITER $CREATE TRIGGER user_log AFTER INSERT ON users FOR EACH ROWBEGINDECLARE s1 VARCHAR(40)character set utf8;DECLARE s2 VARCHAR(20) character set utf8;#后面发现中文字符编码出现乱码,这里设置字符集SET s2 = " is created";SET s1 = CONCAT(NEW.name,s2); #函数CONCAT可以将字符串连接INSERT INTO logs(log) values(s1);END $DELIMITER ;
查看触发器
SHOW TRIGGERS语句查看触发器信息
删除触发器
drop trigger user_log;#删除触发器
在triggers表中查看触发器信息
SELECT * FROM information_schema.triggers WHERE TRIGGER_NAME=‘user_log’;
tips:所有触发器信息都存储在information_schema数据库下的triggers表中
可以使用SELECT语句查询,如果触发器信息过多,最好通过TRIGGER_NAME字段指定查询
- 限制和注意事项
触发器会有以下两种限制:
1.触发程序不能调用将数据返回客户端的存储程序,也不能使用采用CALL语句的动态SQL语句,但是允许存储程序通过参数将数据返回触发程序,也就是存储过程或者函数通过OUT或者INOUT类型的参数将数据返回触发器是可以的,但是不能调用直接返回数据的过程。
2.不能再触发器中使用以显示或隐式方式开始或结束事务的语句,如START TRANS-ACTION,COMMIT或ROLLBACK。
注意事项:MySQL的触发器是按照BEFORE触发器、行操作、AFTER触发器的顺序执行的,其中任何一步发生错误都不会继续执行剩下的操作,如果对事务表进行的操作,如果出现错误,那么将会被回滚,如果是对非事务表进行操作,那么就无法回滚了,数据可能会出错。
- 总结
触发器是基于行触发的,所以删除、新增或者修改操作可能都会激活触发器,所以不要编写过于复杂的触发器,也不要增加过得的触发器,这样会对数据的插入、修改或者删除带来比较严重的影响,同时也会带来可移植性差的后果,所以在设计触发器的时候一定要有所考虑。
触发器是一种特殊的存储过程,它在插入,删除或修改特定表中的数据时触发执行,它比数据库本身标准的功能有更精细和更复杂的数据控制能力。
数据库触发器有以下的作用:
1.安全性。
- 可以基于数据库的值使用户具有操作数据库的某种权利。
- 可以基于时间限制用户的操作,例如不允许下班后和节假日修改数据库数据。
- 可以基于数据库中的数据限制用户的操作,例如不允许股票的价格的升幅一次超过10%。
2.审计。
- 可以跟踪用户对数据库的操作。
- 审计用户操作数据库的语句。
- 把用户对数据库的更新写入审计表。
3.实现复杂的数据完整性规则
- 实现非标准的数据完整性检查和约束。触发器可产生比规则更为复杂的限制。与规则不同,触发器可以引用列或数据库对象。例如,触发器可回退任何企图吃进超过自己保证金的期货。
- 提供可变的缺省值。
4.实现复杂的非标准的数据库相关完整性规则。触发器可以对数据库中相关的表进行连环更新。例如,在auths表author_code列上的删除触发器可导致相应删除在其它表中的与之匹配的行。
-
在修改或删除时级联修改或删除其它表中的与之匹配的行。
-
在修改或删除时把其它表中的与之匹配的行设成NULL值。
-
在修改或删除时把其它表中的与之匹配的行级联设成缺省值。
-
触发器能够拒绝或回退那些破坏相关完整性的变化,取消试图进行数据更新的事务。当插入一个与其主健不匹配的外部键时,这种触发器会起作用。
例如,可以在books.author_code 列上生成一个插入触发器,如果新值与auths.author_code列中的某值不匹配时,插入被回退。
5.同步实时地复制表中的数据。
6.自动计算数据值,如果数据的值达到了一定的要求,则进行特定的处理。例如,如果公司的帐号上的资金低于5万元则立即给财务人员发送警告数据。
存储过程
- 什么是存储过程?
存储过程(Stored Procedure)是在大型数据库系统中,一组为了完成特定功能的SQL语句集,存储在数据库中,经过第一次编译后再次调用不需要再次编译,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。存储过程是数据库中的一个重要对象。
ps:存储过程跟触发器有点类似,都是一组SQL集,但是存储过程是主动调用的,且功能比触发器更加强大,触发器是某件事触发后自动调用;
- 存储过程的创建和使用方法
-- ------------------------------ Procedure structure for `proc_adder`-- ----------------------------DROP PROCEDURE IF EXISTS `proc_adder`;DELIMITER ;;CREATE DEFINER=`root`@`localhost` PROCEDURE `proc_adder`(IN a int, IN b int, OUT sum int)BEGIN #Routine body goes here... DECLARE c int; if a is null then set a = 0; end if; if b is null then set b = 0; end if; set sum = a + b;END;;DELIMITER ;
- 存储过程的优缺点
优点:
①重复使用。存储过程可以重复使用,从而可以减少数据库开发人员的工作量。
②减少网络流量。存储过程位于服务器上,调用的时候只需要传递存储过程的名称以及参数就可以了,因此降低了网络传输的数据量。
③安全性。参数化的存储过程可以防止SQL注入式攻击,而且可以将Grant、Deny以及Revoke权限应用于存储过程。
缺点:
1:调试麻烦,但是用 PL/SQL Developer 调试很方便!弥补这个缺点。2:移植问题,数据库端代码当然是与数据库相关的。但是如果是做工程型项目,基本不存在移植问题。
3:重新编译问题,因为后端代码是运行前编译的,如果带有引用关系的对象发生改变时,受影响的存储过程、包将需要重新编译(不过也可以设置成运行时刻自动编译)。
4: 如果在一个程序系统中大量的使用存储过程,到程序交付使用的时候随着用户需求的增加会导致数据结构的变化,接着就是系统的相关问题了,最后如果用户想维护该系统可以说是很难很难、而且代价是空前的,维护起来更麻烦。
- 存储过程注意事项
不同数据库,语法差别很大,移植困难,换了数据库,需要重新编写;
不好管理,把过多业务逻辑写在存储过程不好维护,不利于分层管理,容易混乱,一般存储过程适用于个别对性能要求较高的业务,其它的必要性不是很大;
- 总结
存储过程速度快,只有首次执行需经过编译和优化步骤,后续被调用可以直接执行,省去以上步骤;
SQL中的join
死锁机制
数据库的恢复、备份
union
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
请注意,UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。
SELECT column_name(s) FROM table_name1UNIONSELECT column_name(s) FROM table_name2
注释:默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
MySQL引擎
转载地址:http://wslrb.baihongyu.com/